Kubernetes v1.14.5 → v1.21.14 升级补遗及经验教训
Contents
距 v1.14.5 - v1.21.14 Kubernetes 跨版本升级记录 发布,忽忽几月。
降本增效大环境下,一边做视频云业务,一边抽空搞 K8s 升级,陆续搞定了 10 来个生产集群的更新。
期间将 Docker 切换成了 containerd,完成了 Container Runtime 更新。同时也拔出萝卜带出泥,遇到不少事故。
下文开始分节补遗并总结经验教训。
Container Runtime 切换及升级
使用 前文 方法实验完一个小集群之后,经团队讨论,一致认定 Container Runtime 为 K8s 集群的重要基础组件,新版本会包括功能迭代、漏洞修复等,理应持续更新。
旧集群运行使用 dockerd 版本 18.06.2-ce,构建时间 2019/02,竟是 5 年前版本了。
最为燃眉的是,该版本偶发无法清理 Sandbox Container BUG,直观感受是 Pod 一直处于 Terminating 状态。
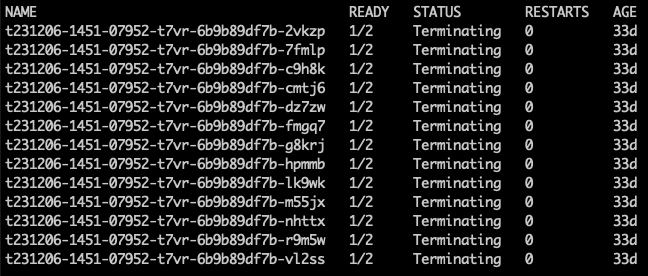
原因是 dockerd 不响应个别 kubelet KillPodSandbox 请求,导致无法完成清理。
Warning FailedKillPod 25m kubelet, woker1188 error killing pod: failed to "KillPodSandbox"
"t231206-1451-07952-t7vr-6b9b89df7b-2vkzp" with KillPodSandboxError: "rpc error: code = DeadlineExceeded
desc = context deadline exceeded"
Warning FailedSync 2m48s (x36 over 22m) kubelet, woker1188 error determining status: rpc error: code =
DeadlineExceeded desc = context deadline exceeded
我们有一部分业务为对外开放的容器应用平台,其对客户实施按量计费。该 BUG 会导致额外计费。
Container Runtime 随 kubelet 一起升级。节点操作步骤变为
- kubectl drain
–ignore-daemonsets –delete-local-data - update kubelet
- update runtime
- kubectl uncordon
update runtime 对应 bash function 如下
|
|
dockerd 所用 storage-driver 为 devicemapper,其采用 LVM 为容器提供持久卷,较新版本已经废弃。步骤 format-container-disk 负责格式化 LVM 盘为 ext4,并将其挂载至路径 /var/lib/containerd。而在之前,脚本已经移除了所有 dockerd 容器并停止了 dockerd 服务。
详细内容见 kube-upgrade.sh runtime 子命令。
使用脚本简化操作
前文 v1.14.5 - v1.21.14 Kubernetes 跨版本升级记录 列述了思路和每个步骤的操作方式。 最终操作中,所有步骤均模块化为如下子命令
- prepare: 在所有 master 节点上安装自 v1.15.12 至 v1.21.14 共 7 个版本的 kubeadm,kubelet 和 kubectl
- cluster: 围绕
kubeadm upgrade apply,在首个 master 节点执行集群层面升级,升级 CoreDNS、kube-proxy、集群配置(kubeadm-config,kubelet-config) 以及该 master 节点上的 control plane,每个 minor 版本都需要操作 - master <mnode>: 围绕
kubeadm upgrade <node>,升级对应 master 节点 kubelet 和 control plane,每个 minor 版本都需要操作 - master-runtime <mnode>: 升级对应 master 节点 Container Runtime,可以在 control plane 升级至 1.21 后操作
- worker <wnode>: 围绕
kubeadm upgrade <node>,升级对应 worker 节点 kubelet 和 Container Runtime,执行 1 次即可,直接自 1.14 升级至 1.21
注:假设所有子命令均在某 master 节点执行,并假设该节点可以 ssh 登陆集群任意节点。
详细内容可查阅 kube-upgrade.sh。
经验 - 新 Runtime 无法自 Registry 拉取镜像
升级 Container Runtime 至 containerd v1.6.28 后,原本 dockerd 可以拉取的镜像,containerd 报 404。
$ nerdctl pull my-register2.example.com/nginx:20231130134315-88-master
my-register2.example.com/nginx:20231130134315-88-master: resolving |-------------------------------|
elapsed:0.5 s total: 0.0 B (0.0 B/s)
FATA[0000] httpReadseeker: failed open: content at https://my-register2.example.com/v2/nginx/manifests/
sha256:e086f32dcf9f00bae7a5d1c4fe7c9760b3af37fe222c28803fd9060d32e4fb27 not found: not found
背景是线上 registry 使用了较老版本,新版本 containerd 与其协议不兼容。解决方式便是升级 registry 为较新版本。
教训 - 所有 Ingress 节点同时升级导致全集群业务不可用
节点(尤其是多个节点同时)升级时,使用 kubectl drain 排空,配合 PDB (PodDisruptionBudget) 可以保证应用可用实例始终保维持在一定数量或比例。
如下所示,设置 maxUnavailable: 1 则集群内应用 apigate 在同一时间段内只会有 1 个实例处于不可用状态。
|
|
假设节点 A 和 B 之上均运行了 apigate 实例,这时尝试同时升级 A 和 B。先执行 kubectl drain A,这时 apigate 不可用为 1。紧接着执行 kubectl drain B 就会检测到 evict 操作会违背 apigate PDB。因此对应操作就进入等待重试状态,直到 apigate 不可用变回 0 时,才会继续执行。
因此,为关键服务设置 PDB 可避免其在集群升级期间不可用。
尽管在设计之初就为所有业务网关均设置了 PDB。但在操作小集群时,仍出现了 2 个 Ingress 节点同时升级导致所有业务流量短时间 500 的事故。
教训:不仅要为业务网关设置 PDB,还需为关键三方应用设置 PDB。典型如
- Prometheus,防止集群 Metrics 或告警出现丢失
- Ingress,防止所有业务流量出现 500
最后,可能还需为极端情况做预案。如某个 Ingress 节点长时间无法升级成功时,可采用添加新节点为 Ingress 节点的方式恢复。
裸金属环境 apiserver 真是高可用吗
升级某个集群时,预期架构为所有 worker 节点通过 keepalived virtual IP 连接至某台 apiserver。这样可以假设 apiserver-1 处于升级期间,流量可以转发至 apiserver-2 或 apiserver-3。
实际情况是,该集群 keepalived 背后 apiserver-2 节点和 apiserver-3 节点在某次操作被注释掉了,并且该配置之前没有入库。 故操作该集群升级时,发生了所有 worker 节点与 apiserver 断连的事故。
worker-1 worker-2 worker-3 worker-1 worker-2 worker-3
| | | | | |
+-------------+------------+ +-------------+------------+
| |
keepalived virtual IP ---- actual ---> keepalived virtual IP
| |
+-------------+------------+ +-------------+------------+
| | | | x x
apiserver-1 apiserver-2 apiserver-3 apiserver-1 apiserver-2 apiserver-3
教训:敬畏生产,明晰 apiserver 架构,操作前做好检查
注:在较新裸金属集群中,已经弃用 keepalived virtual IP 方案,改用了客户端负载均衡方案。即 haproxy 作为 static Pod 跑在 worker 节点,为 kubelet 至 kube-apiserver 提供负载均衡
worker-1
|
haproxy
|
+-------------+-----------+
| | |
apiserver-1 apiserver-2 apiserver-3
| | |
+-------------+-----------+
|
haproxy
|
worker-2
结语:设计可持续演进的软件体系
本次升级只涉及 Kubernetes 容器组件,仍然不包括
- Calico CNI 更新
- Prometheus 更新
- Linux kernel 更新
中小公司不会有专门的基础架构团队分别负责网络、存储、监控、Kubernetes 等。单靠业务团队小部分人兼职处理所有更新,是不可能完成的任务。走流程提需求至运维团队,对方可能会告诉你,没有现成工具可以升级 kernel、Kubernetes。追至负责负责工具的团队时,往往又会以优先级不够之类的理由,要么排期靠后,要么不予处理。
而随着时间流逝,人事更迭,你会发现,24 年做业务,仍旧用着 21 年的 Go 1.16,19 年的 Kubernetes 和 16 年的 Ubuntu 16.04 乃至 10 多年前的 CentOS 6。
一名优秀的工程管理者在引入三方依赖之前,首先应该想清楚已有依赖能否解决业务问题。如果是,则慎重引入。比如当前团队 100% Java,Java 能解决好业务需求,那么就不要为了某些酷炫特性引入 Golang。
如若决定引入,那么就应设计好依赖的持续演进方案。
Author Zeng Xu
LastMod 2024-04-10 17:07
License 本作品采用 知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议 进行许可,转载时请注明原文链接。