v1.14.5 - v1.21.14 Kubernetes 跨版本升级记录
Contents
背景和升级策略
升级集群,首先关注哪些 API 在新版本被废弃 (移除) 了。这一点可以参考官方文档 Deprecated API Migration Guide。 尽管 K8s 最新版本已经是 v1.28.4,但我们线上 K8s 版本仍旧为 v1.14.5。由于业务依赖的不少 API 在 1.22 之后被移除,如
- admissionregistration.k8s.io/v1beta1 MutatingWebhookConfiguration and ValidatingWebhookConfiguration
- apiextensions.k8s.io/v1beta1 CustomResourceDefinition
- coordination.k8s.io/v1beta1 Lease
- extensions/v1beta1 Ingress, networking.k8s.io/v1beta1 Ingress
- networking.k8s.io/v1beta1 IngressClass
这便决定了无法一步到位升到 v1.28.x,而只能采用先升级到 v1.21.x 再逐步往上升级的方式。本文记录 v1.14.5 到 v1.21.14 的操作步骤和问题解决方式。
集群升级方式一般有两种,其一是另建目标集群并逐步迁移完所有服务,其二是逐节点原地升级。 如果选择另建 v1.21.x 并执行迁移的方式,先要在外层网关层实现集群切流功能,再要提前在新集群部署好所有服务,最终逐步完成切流。 考虑到我们没有主从集群切流层、机器资源相对有限、加之集群有状态服务没法简单挪移,因此选择了原地升级。
kubeadm 在 v1.29 之前仅支持逐 minor 版本升级集群,即只能 v1.14 -> v1.15 -> v1.16 -> v1.17 -> v1.18 -> v1.19 -> v1.20 -> v1.21。详细可参考 Upgrading kubeadm clusters。(kubeadm v1.29 之后将支持跨 3 个 minor 版本升级,即可以 v1.26 -> v1.29 -> v1.32,详细可参考 kubeadm#2924 - adjust the kubeadm/kubelet skew policy 🚀
又,从 v1.14 至 v1.21,kubelet 与 apiserver 之间的通信 API 没有发生移除,v1.14 kubelet 可与 v1.14.5 到 v1.21.14 之间的任何版本的 apiserver 通信。 因此升级策略为
- 逐步升级 control plane 至 v1.21
- 一步到位升级 worker node v1.14 至 v1.21
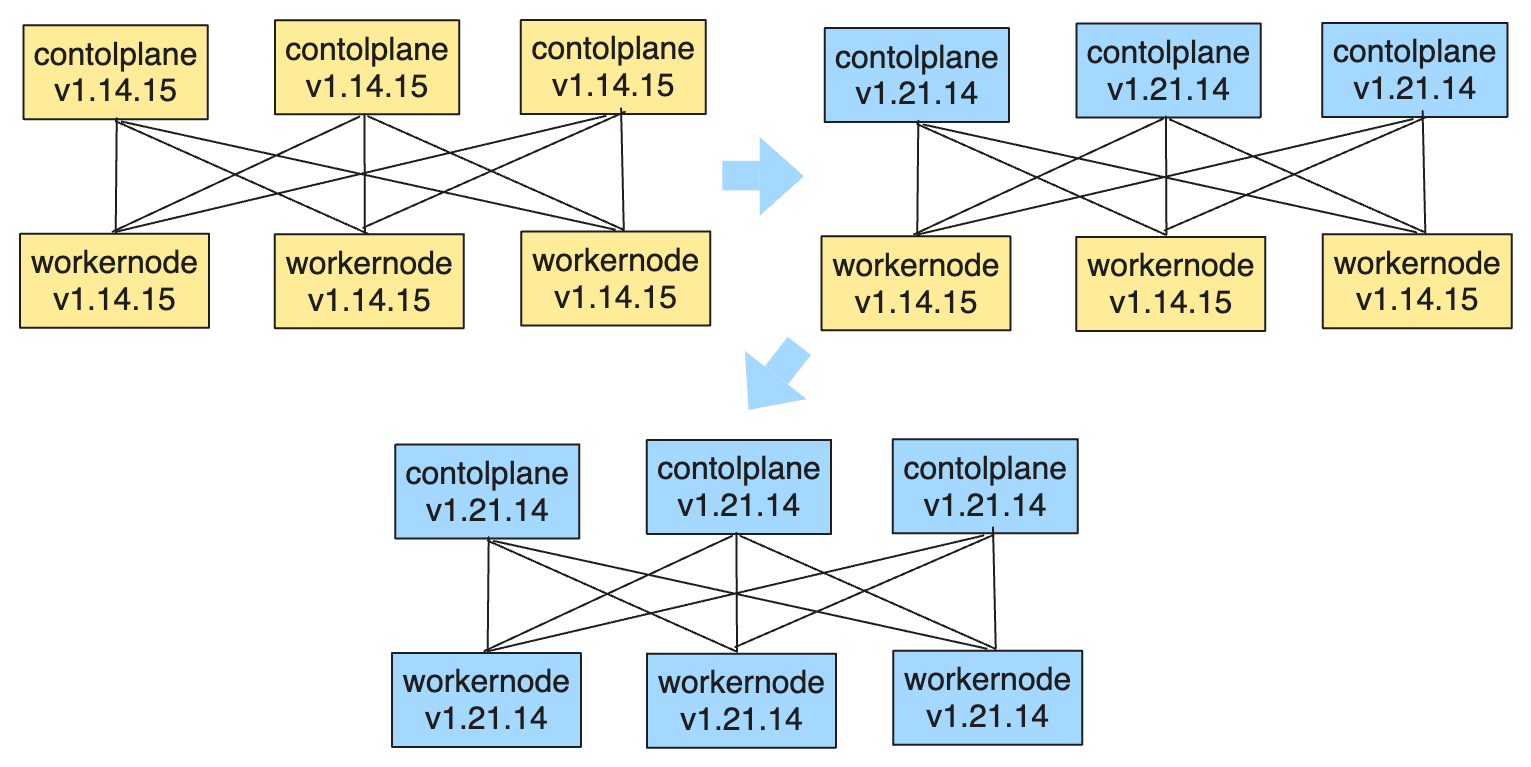
这样做的好处是,即使升级 kubelet 时 Pod Containers 有被重启的风险。这事也只会发生一次。注意
- 升级 kubelet 可能导致 Pod Containers 被重启,见 kubernetes#63814 - kubelet’s calculation of whether a container has changed can cause cluster-wide outages
- 甚至升级 containerd 也可能导致重启 containerd#7845 - CRI: Fix no CNI info for pod sandbox on restart
通常来说,健壮的服务群应能容忍偶发重启或者重新调度。
cluster 级升级(在首个 master 节点执行
|
|
使用 kubeadm upgrade apply <targetVersion> 执行首个 control plane 升级。
|
|
每次执行之后,大致发生以下事情
- apply kube-system 中的集群配置,如 kubeadm-config (i.e ClusterConfiguration),kubelet-config-$VERSION,CoreDNS 以及 kube-proxy ConfigMap
- 更新首个 master 节点上的 kube-apiserver, kube-controller-manager, kube-scheduler(即 /etc/kubernetes/manifests 目录的 static Pod manifests
- 更新集群中的 CoreDNS 和 kube-proxy
所以每次更新完集群之后,需要检查以下服务是否正常运行
- 首个 master 节点上的 kube-apiserver, kube-controller-manager, kube-scheduler
- CoreDNS
- kube-proxy
- CNI Plugin
其他 master 节点更新
下载程序
|
|
执行 kubeadm upgrade node 即可
|
|
对于 control plane 所在节点,执行 kubeadm upgrade node 会
- 获取 kubeadm
ClusterConfiguration,更新 kube-apiserver, kube-controller-manager, kube-scheduler (即 static Pod manifests - 更新 kubelet 启动配置
因此之后只要更换 kubelet 二进制,重启 kubelet 即可完成 control plane 节点更新。
1.14 → 1.15 踩坑记录
-
kubelet 无法启动,原因是 kubernetes#77820 - Remove deprecated Kubelet security controls 移除了该参数
1Nov 28 18:05:27 master-1 kubelet[884]: F1128 18:05:27.064279 884 server.go:156] unknown flag: --allow-privileged解决方式,在 /etc/kubernetes/kubelet.env 移除
KUBE_ALLOW_PRIV="--allow-privileged=true"并在 /etc/systemd/system/kubelet.service 移除$KUBE_ALLOW_PRIV环境变量引用。 -
coredns deployments 新 Pod 无法被创建,原因是 kube-system 中有莫名其妙的 LimitRange 资源,限制了容器最小资源请求最小 CPU 为 100m,最小 Memory 为 100Mi。解决方式,删除 LimitRange 即可。
-
自研 AutoScaler 组件失效,使用 label container_name 突然取不到 CPU Metrics 数据。原因是 1.15 后 kubernetes#76074 - change kubelet probe metrics to counter 移除了 CPU Metrics label container_name。解决方式是修改 Metrics 查询为 label container。如果使用了 label pod_name,也应该修改为 label pod。
1.15 -> 1.16 踩坑记录
更新镜像到 coredns:1.6.2 之后,CoreDNS Deployment 下的 Pod 正常 Running 但一直未 Ready。
|
|
原因是 coreDNS 1.6 之后 readiness serve 改为了插件模式,详见 coredns#3219 - Readiness probe failed 8181: connect: connection refused
解决方式:kubectl -n kube-system edit cm coredns 激活 ready 插件
|
|
1.16 -> 1.17 踩坑记录
|
|
执行完 control plane 和第 1 台 master 升级后,出现 kubelet 报错并无法启动的情况
|
|
原因是 1.17 CSINode 相关处理有了非兼容更新并默认开启,1.17 kubelet 请求到了 1.16 老版本 kube-apiserver 后报错退出。
解决方式
- 控制面升级期间,在当前 master 节点的 kubelet 启动配置中暂时关闭该特性
- 待所有 master 全部升级到 1.17 之后,再写回原来配置即可
|
|
1.18 -> 1.19 踩坑记录
- feature gate
VolumeSubpathEnvExpansion在 1.19 被移除,导致执行kubeadm upgrade后,kube-apiserver, kube-controller-manager, kube-scheduler, kube-proxy, kubelet 均无法启动。解决方式- 提前自 kubeadm ClusterConfiguration 中移除
feature-gates: VolumeSubpathEnvExpansion=true。一般是置空- --feature-gates=。 - 提前自 kube-proxy ConfigMap 移除
feature-gates: VolumeSubpathEnvExpansion=true。 - 提前自 /etc/kubernetes/kubelet.env 移除
feature-gates: VolumeSubpathEnvExpansion=true。(sed -i '/--feature-gates=VolumeSubpathEnvExpansion=true \\/d' /etc/kubernetes/kubelet.env
- 提前自 kubeadm ClusterConfiguration 中移除
- 触发 Prometheus 告警: 😱🚀 KubeScheduler/KubeControllerManager has disappeared from Prometheus target discovery。
原因是 Prometheus 使用 HTTP EndPoints
:10251/ready 探测 KubeScheduler 是否就绪,但在 1.19 移除了这一默认端口。 详见 kubeadm#2207 - remove –port from kube-controller-manager and kube-scheduler 解决方式,自己 kube-scheduler 和 kube-controller-manager manifest 删除启动参数1 2up{endpoint="http-metrics",instance="10.40.34.34:10251",job="kube-scheduler",namespace="kube-system",pod="kube-scheduler-master0",service="basic-kube-scheduler"} 0- --port=0(sed -i '/- --port=0/d' /etc/kubernetes/manifests/kube-scheduler.yaml /etc/kubernetes/manifests/kube-controller-manager.yaml - 部分 Webhook 证书突然失效
解决方式,更新 kube-apiserver manifests,给 Pod 增加环境变量即可
1 2 3 4 5 62023-11-30T14:46:44.577+0800 ERROR ... err: Internal error occurred: failed calling webhook \"mutate-deploy.x.com\": Post \"https://x.kube-system.svc:443/mutate-deployment?timeout=30s\": x509: certificate relies on legacy Common Name field, use SANs or temporarily enable Common Name matching with GODEBUG=x509ignoreCN=0"该方式在 1.23 前有效,详见 GKE: Ensuring compatibility of webhook certificates before upgrading to v1.231 2 3env: - name: GODEBUG value: "x509ignoreCN=0"
1.19 -> 1.20 注意点
- kubelet 会使用 pause:3.2,需要保证 pause:3.2 在内网可拉取
- v1.19 至 v1.20 最大变化就是废弃了
apiserver serve on an insecure port,因此在升级前应该修改 kubeadm ClusterConfiguration 移除 apiserver 参数--insecure-bind-address和参数--insecure-port。同时应该检查左右客户端 kubeconfig,如果使用了 HTTP 连接 kube-apiserver,应该更新至 HTTPS 版。 - 为兼容 Prometheus HTTP 探测 kube-scheduler 和 kube-controller-manager,应该继续执行
sed -i '/- --port=0/d' /etc/kubernetes/manifests/kube-scheduler.yaml /etc/kubernetes/manifests/kube-controller-manager.yaml - 1.20 kubelet 移除了 endpoint
metrics/resource/v1alpha1,如果 Prometheus 配置了从该路径爬取 Metrics 的 ServiceMonitor,需修改对应资源,改成metrics/resource
1.20 -> 1.21 注意点
- kubelet 会使用 pause:3.4.1,需要保证 pause:3.4.1 在内网可拉取
- 为兼容 Prometheus HTTP 探测 kube-scheduler 和 kube-controller-manager,应该继续执行
sed -i '/- --port=0/d' /etc/kubernetes/manifests/kube-scheduler.yaml /etc/kubernetes/manifests/kube-controller-manager.yaml - 1.21 feature BoundServiceAccountTokenVolume 默认启用后,ServiceAccount 凭证从 Secret 挂载改为动态 Token 获取。按照声明来看挂载权限无差异。但在生产集群中,Pod Container 设置
securityContext.runAsUser: 101以非 root user 运行时,读取 token 文件报错open /var/run/secrets/kubernetes.io/serviceaccount/token: permission denied(container image: quay.io/kubernetes-ingress-controller/nginx-ingress-controller:0.31.0)。解决方式:为 Pod 设置1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26# before 1.21 - name: nginx-ingress-serviceaccount-token-vqxzw secret: defaultMode: 420 secretName: nginx-ingress-serviceaccount-token-vqxzw --- # after 1.21 volumes: - name: kube-api-access-xbwws projected: defaultMode: 420 sources: - serviceAccountToken: expirationSeconds: 3607 path: token - configMap: items: - key: ca.crt path: ca.crt name: kube-root-ca.crt - downwardAPI: items: - fieldRef: apiVersion: v1 fieldPath: metadata.namespace path: namespacespec.securityContext.fsGroup: 65534,确保所有 container 对挂载目录有读取权限。
系统级镜像坑点
如因内网环境或者其他原因导致国外镜像不可达,应该使用 kubeadm apply <targetVersion> --dry-run 打印执行结果,重点 grep 如下组件镜像并提前做好分发
- CoreDNS
- pause
小节 cluster 级升级开头的镜像分发是走完整个流程的成果。
任意 worker 节点更新
走完 control plane 节点更新,也就踩完了普通 worker 节点的坑。脚化处理即可。找一台可以登陆所有 worker 的机器,准备脚本 upgrade-worker.sh
|
|
然后按照实际业务情况,分批次完成 kubelet v1.14 至 v1.21 升级。
|
|
注意: kubelet 更新时所涉及的参数更新,如 参数移除, feature-gates 移除, pause container 更新 等,具体因实际集群而异。
总结
集群升级概要
- 先测试集群后生产集群,先小集群后大集群
- 提前备份 etcd,虽然本文没用上备份 👻
- 查阅 Kubernetes CHANGELOG,注意新版本核心组件的参数移除,尤其是 feature gates 移除会涉及所有
kube-打头组件 - 提前
kubeadm upgrade <version> --dryrun检查新版本镜像,做好 CoreDNS 和 puase 容器镜像分发 - upgrade 完成后,检查 CoreDNS 和 kube-proxy 所有 Pod 状态,确保更新完成;检查集群 DNS 功能是否正常;检查集群 Service 功能是否正常
- 每次 upgrade 完成,检查 Operator/Controller 和关键业务应用是否正常(关注日志/监控/告警),检查核心 API CRUD 是否正常(防止 Webhook 崩坏)
Container Runtime 更新部分、最终操作方式和脚本请查阅 Kubernetes v1.14.5 → v1.21.14 升级补遗及经验教训。
参考链接
- TauCeti.blog’s Kubernetes upgrade notes: 1.14-1.15, 1.15-1.16, 1.16-1.17, 1.17-1.18, 1.18-1.19, 1.19-1.20, 1.20-1.21
- Deprecated API Migration Guide
- Upgrading kubeadm clusters
- Kubernetes CHANGELOG
Author Zeng Xu
LastMod 2024-10-09 15:55
License 本作品采用 知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议 进行许可,转载时请注明原文链接。